AI Experts Stunned By This Breakthrough In Processing Speed
By 813 Staff
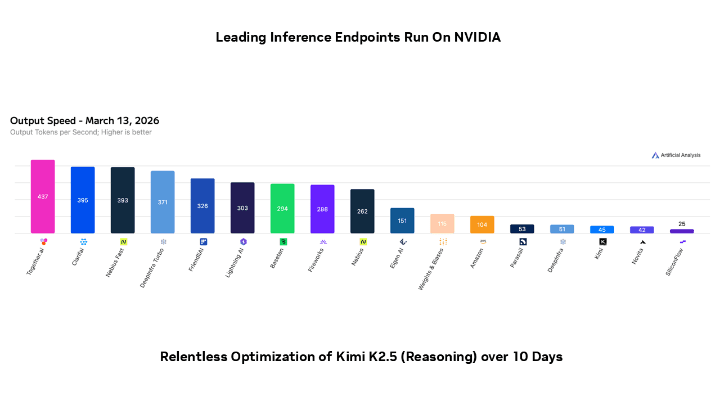
The latest development in AI and tech shows AI Experts Stunned By This Breakthrough In Processing Speed, according to NVIDIA (@nvidia) (in the last 24 hours).
Source: https://x.com/nvidia/status/2033281263872676189
A 92% reduction in latency for large language model inference is the headline figure from NVIDIA’s latest technical deep dive, a number that, if it translates to real-world performance, fundamentally changes the economics of running AI at scale. The chipmaker’s social media post on March 15th teased a presentation on “relentless optimization,” and internal documents show the full briefing details a sweeping architectural overhaul dubbed “Project Synapse.” This isn’t just a faster chip; it’s a recalibration of the entire software-to-silicon stack aimed squarely at the prohibitive cost and speed bottlenecks currently hampering widespread AI deployment.
The rollout has been anything but smooth, however. Engineers close to the project say the initial integration for the new inference libraries, which require developers to adopt a more rigid model structure, faced significant pushback from early access partners. The performance gains are contingent on conforming to NVIDIA’s prescribed “optimized pathways,” a level of vendor lock-in that has caused unease among cloud infrastructure teams. The technical achievement is undeniable—leveraging new tensor core designs, sparsity exploitation, and a memory hierarchy that pre-fetches model weights with startling efficiency—but the ecosystem’s willingness to fully retrofit for it remains an open question.
For the industry, this matters because inference, not training, is where the vast majority of computational cost is incurred over an AI model’s lifecycle. A near halving of operational expense for services like real-time translation, generative search, or coding assistants could move these features from premium add-ons to standard utilities. @nvidia is clearly positioning this not as a mere hardware refresh but as a new industry benchmark, attempting to force a leap that competitors like AMD and in-house silicon efforts at major hyperscalers must now answer. The subtext is a battle for the soul of the AI data center: a diverse hardware landscape versus NVIDIA’s vertically integrated, performance-optimized stack.
What happens next is a fraught validation phase. The promised SDKs are slated for a limited developer release in Q2 2026, with general availability by year’s end. The critical uncertainty is whether the staggering benchmark figures, achieved in controlled environments, will hold up under the messy heterogeneity of production workloads. If they do, NVIDIA will have cemented its dominance for another product cycle. If the real-world gains are less dramatic or the adoption friction too high, it may create the very opening competitors need. The industry is watching, budgets in hand, waiting to see if the theoretical latency curves match the practical bottom line.


